
Mastering serialization at Xperience by Kentico
Lukasz Skowroński - Senior Solutions Architect
7 Oct 2024
Concept of serialization as a part of development process
Serialization is very often used by the development teams to share the latest changes through a code repository with the whole team doing software development. It is extremely important when a system that you use allows you to define your custom data types (like XbK). Data types defined on the system level are linked tightly to the code – they cannot work separately. If one developer creates a new custom data type, writes a code based on it, and pushes the code to the repository, without sharing the custom data type definition with the others, local instances of the team will be broken. The custom data type has to be added to the repository too. Serialization can help with it as can save the complex and flexible objects into the files that are later added to the repository. When the code and serialized data types and the data are in the repository, your development team can have a unified state of the environments.
During software development serialization runs in two directions:
- Software developer serializes local changes and adds these changes to the repository so the rest of the team can use it
- Software developer deserializes changes pulled from the code repository and synchronizes the local environment with the changes of other team members
Concept of serialization as a part of deployment process
Serialization can also be used as a part of the deployment process. Data that is serialized and added to the code repository can be easily propagated between the servers. In the process of artifact preparation, you can also run some additional operations on the files – for instance, exclude the data you do not want to see in the targeted environment. When the artifact is deployed there has to be also a mechanism that runs data synchronization – sometimes the mechanism is built-in, and sometimes it is an external application.
During a deployment process serialization runs in one direction:
- Deployment engine, pulls the latest artifact and synchronizes environment database with the latest changes (deserialize data)
How does Xperience by Kentico support the serialization
XbK has a two built-in features that share the implemented serialization mechanism. These features can be used to share the changes within the development team or to deploy the changes on your environments. At first glance names of the features may not be very straightforward, let’s then decode the names and explain when every one of them should be used.
XbK Continues Integration
Continues Integration feature is designed to synchronize data during development. It should not be used for the deployments:
- due to the performance constraints (triggered on every change)
- because it by default deletes the data during synchronization
Continues integration can be enabled on every environment (local, dev, qa, uat, prod) but in practice it should be enabled only on local environments of software developers working on the changes.
To enable CI, you have to go the Configuration > Settings > Synchronization > Continues Integration tab and check the checkbox from the figure below:
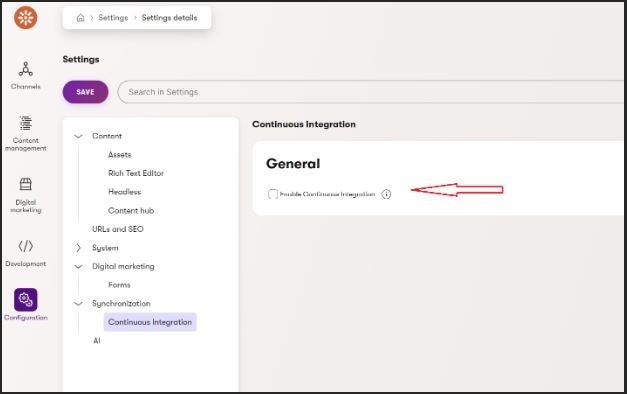
If you want to run CI on a local environment (for instance because you have just pulled the latest version of code from the repository) you can use the following command:
dotnet run --kxp-ci-restore --project .\src\Projects\Namespace.Web\Namespace.Web.csproj –verbose
And all of the data should be synchronized. Be careful though, your data can be deleted at this point. I would recommend to verify if you have any not committed changes by running a CI store command:
dotnet run --kxp-ci-store --project .\src\Projects\Namespace.Web\Namespace.Web.csproj –verbose
Then you can consciously decide what should be removed or updated and what should not be touched.
XbK Continues Deployment
The Continues Deployment feature is something that you will not find in the settings of Kentico and it is used for different purposes (even when it still uses serialized data). CD mechanism is also used to synchronize the data changes in environments. In this case synchronization has to be triggered on request.
When you deploy your changes on the on-premise servers, you can run it with a command:
dotnet run --kxp-cd-restore --repository-path "`$CDRepository" --project .\src\Projects\Namespace.Web\Namespace.Web.csproj –verbose
When you deploy your changes into the SaaS environment, this command is triggered by Kentico, the only thing that you have to be sure of, is the structure of the artifact that you deploy – so Kentico can find the serialized data ( CDRepository folder has to be in the root folder of the package).
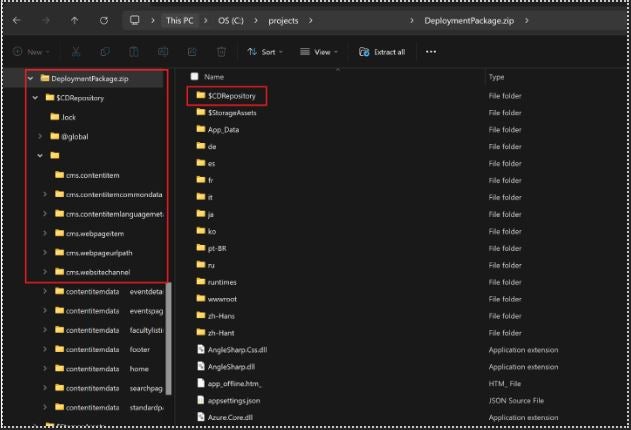
In theory, you can also use the Continues Delivery feature to synchronize your local changes – if you find a good use case for it – in practice though, it is better to use Continues Integration for it.
CI and CD configuration deep dive
In this section we will not cover the basics of CI and CD configuration, you can find them in the official documentation:
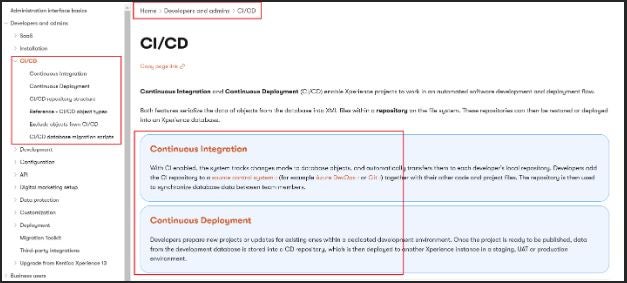
If you check the details described in the documentation you will find out that both of the mechanisms store configuration inside the repository.config file.
At this point it is worth noticing that even though both mechanisms use repository.config, there is a small difference related to the mode of synchronization.
Continues Deployment repository.config contains RestoreMode setting that allows you to decide if you want to:
- only create items
- create and update existing items
- operate the same way as Continues Integration (full mode creating, updating, deleting items)
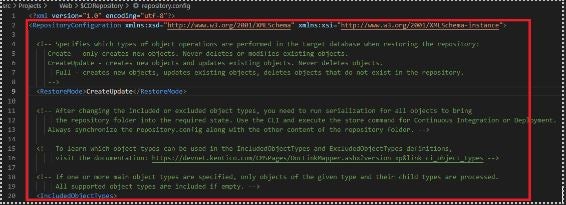
Continues Integration repository.config though, does not contain that section and synchronization always works in a Full mode.
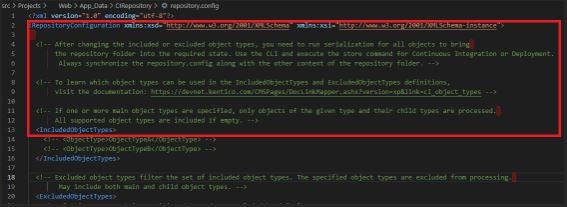
After the first part, the rest of the configuration looks exactly the same and it is divided into three sections:
- IncludedObjectTypes (lists types that you want include)
- ExcludedObjectTypes (lists types that you want exclude)
- ObjectFilters (filters out objects during the serialization)
By default, Kentico excludes cms.settingskey to ensure that none of the keys will be accessible on the level of the repository, and also because you may have different configurations on every environment and this data should not be overwritten during the synchronization.

Based on our experience we decided to not exclude anything else for CI, but we have many types excluded for the CD:
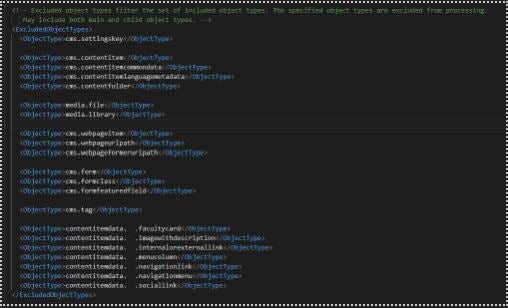
We exclude all of the media files, content items, forms, pages and our custom types.
Custom types are not listed in the documentation, and you need to remember about composing that list on your own. The rule is that the name of these objects starts with “contentitemdata.” And then you have lowercased types that you defined in your Xperience by Kentico.
If you are not sure what is the correct value, you can always double-check it in the folders created by CI that most like you will find in App_Data > CIRepository folder of your main project:
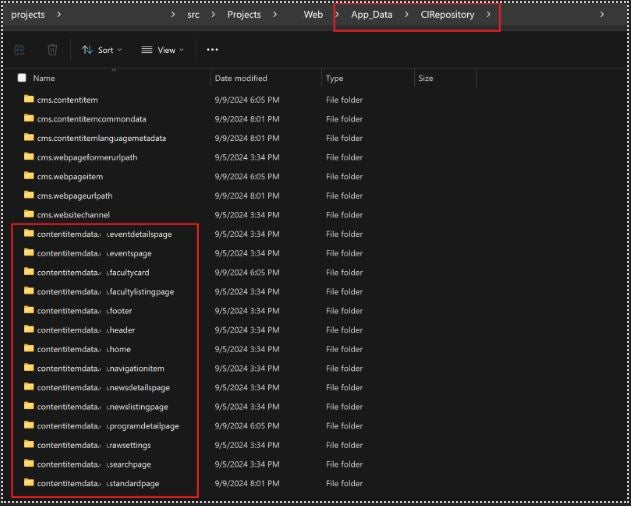
You should exclude these items for CD whenever your QA or Content Editors team starts adding their content – otherwise, every time you deploy changes you put yourself at risk of losing the manually created data.
The last section that allows filtering the items is something that is found as feature less useful than the others and we will explain why in a minute. Some of you may still need it, so here is the example of usage that we had configured at the beginning (we were excluding Home page from the serialization).
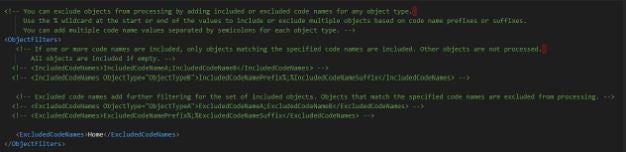
We would found these sections much more useful if:
- It does not allow to filter items only by type & name (does not scale very well as you may need to add many exceptions)
- It does not allow to use wildcard (*) but only at the end of the item name (wildcard can catch many more items that you want to)
- Wildcard wasn’t the only filter (lack of regex support does not help with keeping everything under control)
- It does not use types and names only (it is not possible to use the paths – so you do not have control over the folders or pages)
Summary
As you can see, serialization is a powerful tool that you can use on every single step of the release cycle of your Xperience by Kentico projects. From development through deployments, it can automate the way you deal with the data stored inside Kentico and remove the issue of non-synchronized databases. Learn basics and do not be afraid of experimenting with the tools and usage of them as the flexibility provided by Kentico can sometimes surprise you.
Ready to streamline your Kentico projects with serialization? Contact us to learn how we can help!

Lukasz Skowroński
For over 18 years, I have developed numerous solutions for customers worldwide. I specialize in DXP platforms, including Sitecore, Xperience by Kentico, and various CMSs such as Umbraco. So far, I have been awarded nine times with the Sitecore MVP title, once with the Kentico MVP. I continuously support various communities by organizing local user groups and larger conferences like Sitecore User Group Conference Europe (SUGCON Europe), as well as by sharing knowledge through blog posts.
Share on social media